2025年的大模型训练和大模型应用与之前有什么差别?来自前OpenAI研究人员、特斯拉FSD负责人Andrej Karpathy的年度总结:2025年6个大模型不一样的地方
作为特斯拉前 AI 主管、OpenAI 创始成员,Andrej Karpathy 一直是 AI 领域最敏锐的观察者之一。他不仅擅长构建模型,更擅长从工程实践中提炼出底层的范式位移。
昨天,Karpathy 发布了《2025 LLM Year in Review》,对过去一年大模型领域发生的结构性变化进行了深度复盘。在这篇总结中,他没有说今年大模型具体的模型参数和性能,而是将目光投向了推理范式的演进、Agent 的真实形态以及“Vibe Coding”的新型开发模式。
原文并非“学术综述”,而是作者以个人视角挑选出他认为“概念上改变格局、并且有点出乎意料的范式变化(paradigm changes)”。我们在这里也聊聊大神眼中的2025年的大模型情况。Karpathy 原文包含6个不同的点,我们把Cursor和Claude Code合并成一个了。原文末尾也有 Karpathy 的博客地址链接。
一、大模型训练范式转移:RLVR 成为新的核心增长点,从小补丁步骤变成核心流程
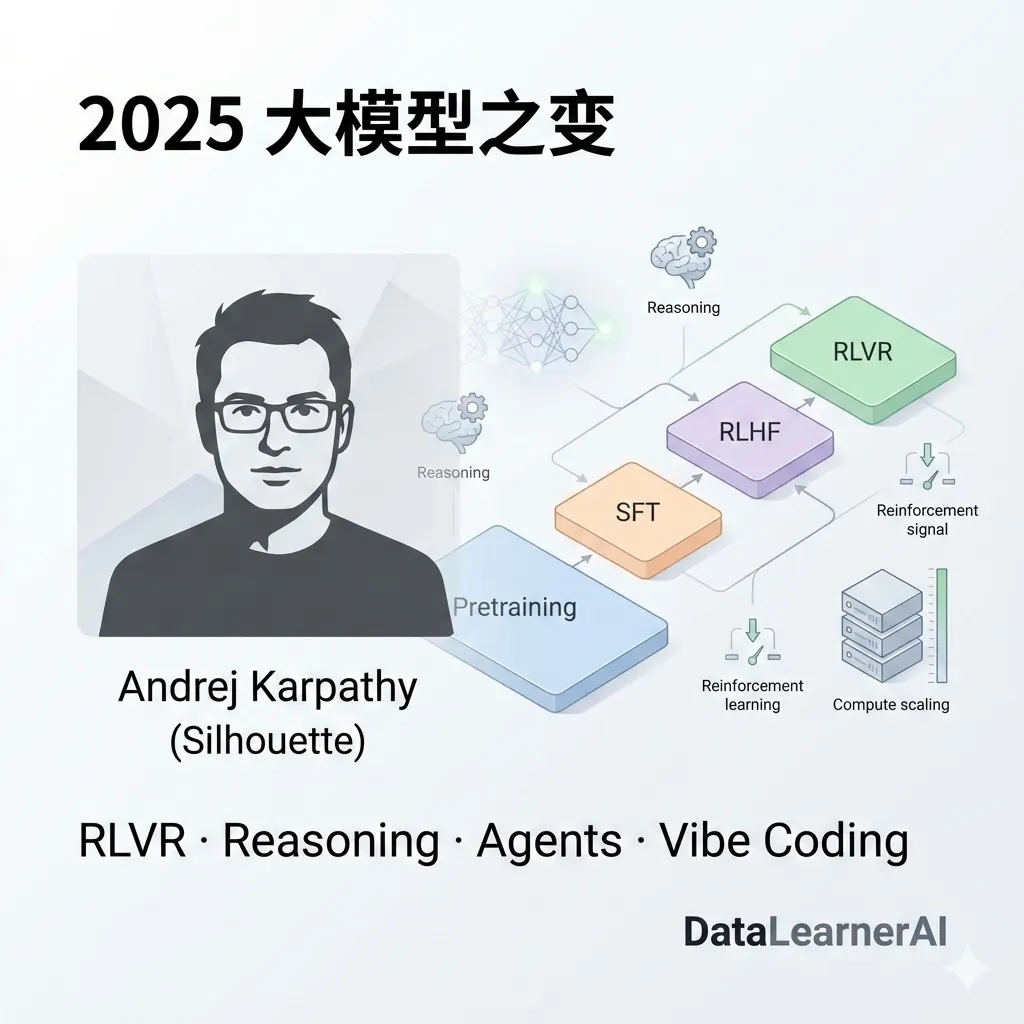
在 2025 年之前,主流的大模型生产包含三个阶段:
- 预训练(Pretraining):用海量文本做自监督学习(典型是 next-token prediction),让模型获得语言建模、知识记忆、通用模式识别能力。通常是最“重”的阶段:数据量最大、训练步数多、算力消耗最高,也是决定模型底座能力上限的重要来源。
- SFT(指令微调):用人工标注的“指令—回答”数据,把模型从“续写器”调成“会按指令办事的助手”。相比预训练更“薄”(原文用 thin/short),计算量通常小得多,属于在现有底座上做较短的微调。
- RLHF(人类反馈强化学习)负责对齐:通过人类偏好打分/比较,训练一个奖励模型(reward model),再用强化学习让模型输出更符合人类偏好(更有帮助、更无害、更符合风格)。同样通常是相对“短”的阶段,算力开销比预训练小很多,但对体验影响大。
这三段式在一段时间里是“稳定且被证明有效的配方”。而 2025 年的变化是:出现了一个新的、非常吃算力的主要阶段,即基于可验证奖励的强化学习(RLVR, Reinforcement Learning from Verifiable Rewards)。
RLVR 是一种强化学习范式,它依然属于强化学习的广义框架,但与传统从人类反馈学习(RLHF)不同,它 用可程序化、可验证的奖励信号来训练大模型,比如直接验证答案是否正确的规则或测试,而不是依赖人工评判。模型只有在输出能够通过这些客观检验时才获得奖励,从而鼓励模型产生更可靠、可验证的结果。它和RLHF核心差异是 奖励不是来自人类主观偏好,而是来自可自动验证的客观结果:对就是对、错就是错。它的核心特点是:
- 技术逻辑的转变:传统的 SFT 和 RLHF 本质上是“轻量微调”,且极度依赖人类的偏好数据。而 RLVR 是在数学、代码等具备“客观真理”的环境中,让模型通过自动验证的奖励信号进行大规模优化。
- “推理”的涌现:通过在可验证环境中不断试错,模型自发地学会了拆解步骤、中间计算以及回溯策略。这解释了为什么 DeepSeek R1 或 OpenAI o3 能表现出类似人类“思考”的过程——它们并非在模仿人类的思考路径,而是在寻找能够通过验证的最优策略。
- 计算重心的位移:RLVR 是一种高“能力/美元比”的训练方式。2025 年,各大实验室将原本计划用于预训练的算力大量投入到 RLVR 中。结果是,模型参数量可能没有质变,但由于增加了“推理时间(Test-time compute)”,模型的实战上限被大幅拉高。
在Karpathy观察中它已经成为新的事实标准(de facto new major stage),即几乎当前主流的所有的大模型训练都有这个过程。关于RLVR更多的介绍可以参考DataLearnerAI的博客:基于可验证奖励的强化学习(Reinforcement Learning with Verifiable Rewards, RLVR)的介绍:为什么 2025 年,大模型训练的重心开始发生迁移?
二、锯齿状智能:2025年我们能更加清晰理解大模型的智能
Karpathy 关于 2025 年大模型技术的第二个核心判断,是我们终于开始以一种更直观的方式,去内化和理解大语言模型智能的“形态”本身。换句话说,行业第一次在直觉层面“看清了”LLM 的智能到底长什么样,而不再习惯性地用“像人”“像动物一样变聪明”的老比喻去套它。
围绕这一点,Karpathy 提出了一个极具冲击力的隐喻:我们并不是在进化一种新的“动物”,而是在召唤某种“幽灵”。这一判断并非来自哲学想象,而是源于 2025 年行业里愈发普遍的一类现象——LLM 的能力提升并不是整体、平滑、均匀发生的。相反,它们往往在某些可验证(verifiable)的任务邻域中突然“刺穿”,例如有明确对错判定的数学、代码和形式化推理问题;而在其他区域,模型依然脆弱,极易被误导。
这种明显不连续、非均匀的能力分布,使得 LLM 呈现出一种近乎“锯齿状(jagged)”的智能结构,也让“像动物一样逐步成长”的类比变得越来越站不住脚。两种智能形态背后的差异,本质上来自完全不同的优化逻辑。大模型锯齿状的智能在此前Ilya Sutskever的访谈中也谈到了,大家也可以参考此前DataLearnerAI的博客:Ilya Sutskever访谈深度解读:关于大模型的瓶颈、人类智能的优势、模型泛化不足以及5-20年后超级智能会出现的真正问题

如果你认真看,人类智能本身也并不是一个平滑、均匀的球体,只是“锯齿的方向完全不同”。人类是“多方向、低峰值”的锯齿,AI 是“少方向、超高峰值”的锯齿。
一方面,人类神经网络是在长期进化中,为部落生存、环境交互与具身决策而塑形的;另一方面,LLM 的神经网络则被明确地优化去模仿人类文本、在可验证问题中获取奖励,以及在 Arena 这类人类反馈体系中赢得更高评分。目标函数不同,得到的“智能形态”自然也截然不同。
也正因为 RLVR 主要发生在可验证领域,LLM 的能力才会在这些局部空间中被不断放大,最终表现为极度不平衡的结构:模型可以在高等数学或复杂推理上展现出近乎博学家的水平,却仍可能在常识判断、语境理解,甚至一次精心设计的 jailbreak 面前,显得像个困惑的小学生。
在这一背景下,Karpathy 对 2025 年各类 Benchmark 表现出了近乎本能的不信任。当榜单本身成为一种“可验证环境”时,实验室围绕这些嵌入空间进行针对性 RLVR 优化几乎是不可避免的结果。刷榜正在演化成一种新的技术艺术,而高分,也越来越不再等同于通往 AGI 的方向。
三、应用层的新博弈:大模型正在从网页里的服务迁移到驻留在本地计算机环境的新的计算层
如果说 2025 年我们第一次在直觉上看清了大模型智能的形态,那么几乎在同一时间,另一条变化也在应用层悄然成形:LLM 正在从“网页里的工具”,迁移成“常驻在本地计算环境中的新一层”。

这里有2个例子:Cursor与Claude Code,它们代表了2025年LLM 应用的形态正在发生的两次关键分裂:
第一,应用层的“厚度”竞争。
以 Cursor 为代表的应用证明了“上下文工程”和“多调用编排(DAG)”的价值。Karpathy 认为,大模型实验室未来更倾向于培养“全能大学生”,而垂直领域的应用层则负责将这些大学生组织成专业的团队,并提供私有数据和反馈环。
第二,Agent 运行环境的“主权”移交。
Claude Code 的出现被视为 Agent 的首个说服力原型。与 OpenAI 坚持的云端容器方案不同,Claude Code 运行在用户的本地环境(localhost)。这种“AI 住在你的电脑里”的范式,比云端 Agent 更能触及开发者的真实上下文。
Cursor 经常被拿来作为例子,但它的意义并不在于“一个更聪明的 IDE”。真正重要的是,它让开发者第一次明确感受到:LLM 不再只是被调用的服务,而是可以深度嵌入工作环境、长期存在、持续协作的系统组成部分。它不只是回答问题,而是在代码、文件和上下文之间“在场”。
Claude Code 将这一趋势推进得更进一步。所谓 AI that lives on your computer,并不是一个修辞性的说法,而是一次边界的下沉:AI 开始直接接触文件系统、终端、进程和真实状态,与人类共享同一套计算原语。在这种模式下,用户不再是唯一的操作主体,AI 也不再只是建议者,而是参与执行、接受反馈、被约束的协作方。
这背后,应用层的竞争逻辑已经发生了明显变化。过去,LLM 应用的核心博弈集中在模型能力、提示词设计和交互界面;而现在,焦点正在转向谁能让 AI 更稳定地“待在系统里”,谁能管理长期上下文,谁能把模型嵌入到真实的工作流与终端环境中。从 Cursor 到物理终端,争夺的其实是 LLM 能够触达的最底层计算接口。
这种变化并非偶然。正是因为大模型的能力本身呈现出明显的锯齿状结构,它们才不适合被当作一次性回答引擎,而更适合以“在位代理”的形式存在:在强项上自动放大效率,在弱项上通过人类监督、工具约束和真实环境反馈来兜底。与其追求一次性更聪明的回答,不如让模型在真实系统中持续工作、持续暴露短板、持续被修正。
从这个角度看,Cursor 和 Claude Code 所代表的,并不是某一类产品形态的胜负,而是一个更长期的问题:未来的大模型,究竟是偶尔被召唤的工具,还是长期居住在我们计算环境中的协作对象。而 2025 年,应用层已经开始给出它的答案。
四、Vibe Coding:当编程从“精确控制”转向“状态引导”
如果说 Cursor 和 Claude Code 标志着 AI 开始“住进”计算环境,那么 Vibe Coding 则进一步改变了人与代码的协作方式。它并不是某种语言或工具,而是一种新的工作范式:人类不再精确描述每一步实现,而是通过持续的语境、意图和反馈,引导代码整体朝某个方向演化。关于Vibe Coding的基本概念和介绍也可以参考DataLearnerAI此前6月份发布的博客:最近很火的基于人工智能(AI)的vibe coding是什么?它和传统软件编码之间有什么区别?
在这种模式下,代码变得廉价且临时。为了验证一个想法或复现一个 Bug,开发者可以让模型快速生成整套实现;人类关注的重点,也从理解具体语言和框架,转向维持“意图是否连贯”。

这与传统“逐行构造、逐步控制”的开发方式形成了鲜明对比。Vibe Coding 更像是在维护一种整体状态:系统是否仍朝着预期架构收敛,修改是否破坏了隐含不变量,代码整体是否“还对劲”。实现细节可以被反复推翻甚至完全重写,人类更多承担的是方向性校准,而非逐行审核。
但Vibe Coding 对经验丰富的工程师和初学者的效果几乎相反。
- 对老手而言,vibe 是高度压缩的工程直觉,能够快速判断结构是否危险、抽象是否失衡,并在偏离时拉回;
- 而对新手来说,当实现细节被模型接管、全局约束又难以表达时,这种方式很容易退化为“能跑但不可维护”的拼装。
这种分化在 2025 年变得尤为明显,并不只是因为模型更强,而是因为 LLM 已经开始以常驻、在位的方式参与开发流程。当编程从一次次生成请求,转变为长期协作过程时,vibe 本身就成为一种可感知、可调节的对象。
从工程角度看,Vibe Coding 并不是降低严谨性,而是重新分配严谨性的位置。人类负责目标、边界和不可违背的约束;模型负责实现路径和局部试探。代码质量不再主要来自“写得是否精确”,而是来自反馈回路是否足够密集。
因此,Vibe Coding 并不是“把编程交给 AI”,而是承认代码已经从一个完全可控的对象,变成了一个需要被持续引导的过程。开发者的角色,也随之从实现者转向调节者,从逐行控制转向整体判断。
五、属于LLM的GUI:下一代计算范式开始寻找自己的界面
2025 年大模型应用层另一个重要趋势,是 Nano Banana 这类“原生图像能力”模型对 GUI 的直接冲击。Nano Banana 是 Google 在 2025 年展示的一类 Gemini 模型能力形态,其核心特征并不在于“会画图”,而在于两点:对图像的精确理解,以及在多轮交互中保持高度一致、可控的图像生成与编辑能力。模型不仅能识别图像中细粒度的结构、文字和语义关系,还能在反复修改中稳定地“只改该改的地方”。
这里的关键并不是“图像生成变强了”,而是它把两项长期缺失的能力同时补齐:图像理解足够精确,以及图像生成/编辑足够一致、可控。这两项能力叠加后,GUI 才第一次变得像一种“新的人机接口”,而不只是给模型加了个作图工具。

如果 LLM 是新的计算核心,那么它就不应该长期只通过“文本对话”与人类交流。**对人而言,更自然的交互形式应当是图像、信息图、白板、幻灯片、动画、网页应用,甚至是可操作的空间结构,而不是一行行生成的文字。
Nano Banana的出现,使得图像第一次具备了“可操作性”。用户不再需要把视觉世界翻译成冗长的文字描述,而是可以直接指着图像本身提出修改意图——圈选、对比、强调、保持一致。这种交互在过去的多模态模型中要么不精确,要么不可复现,因此始终停留在演示层面。

也正是在这里,Nano Banana 第一次明确展示了一种可能的 LLM GUI 雏形:图像不再只是生成结果,而成为可以被持续理解、修改和校准的交互载体。
总结:大模型能力的边界与未实现的潜能
回顾 2025 年,大模型展现出一种矛盾的特质:它比预想中更聪明,同时也比预想中更笨。
Karpathy 的结论保持了极客式的冷静:模型能力本身依然是长期的决定性因素,而行业目前甚至还没挖掘出当前模型潜力的 10%。随着 RLVR 范式的成熟和推理算力比例的增加,大模型的演进路径正变得前所未有的开阔,但也更需要我们摆脱“拟人化”的思维定式,去理解那团被算力和奖励信号召唤出来的“幽灵”。
欢迎关注 DataLearner 官方微信,获得最新 AI 技术推送
