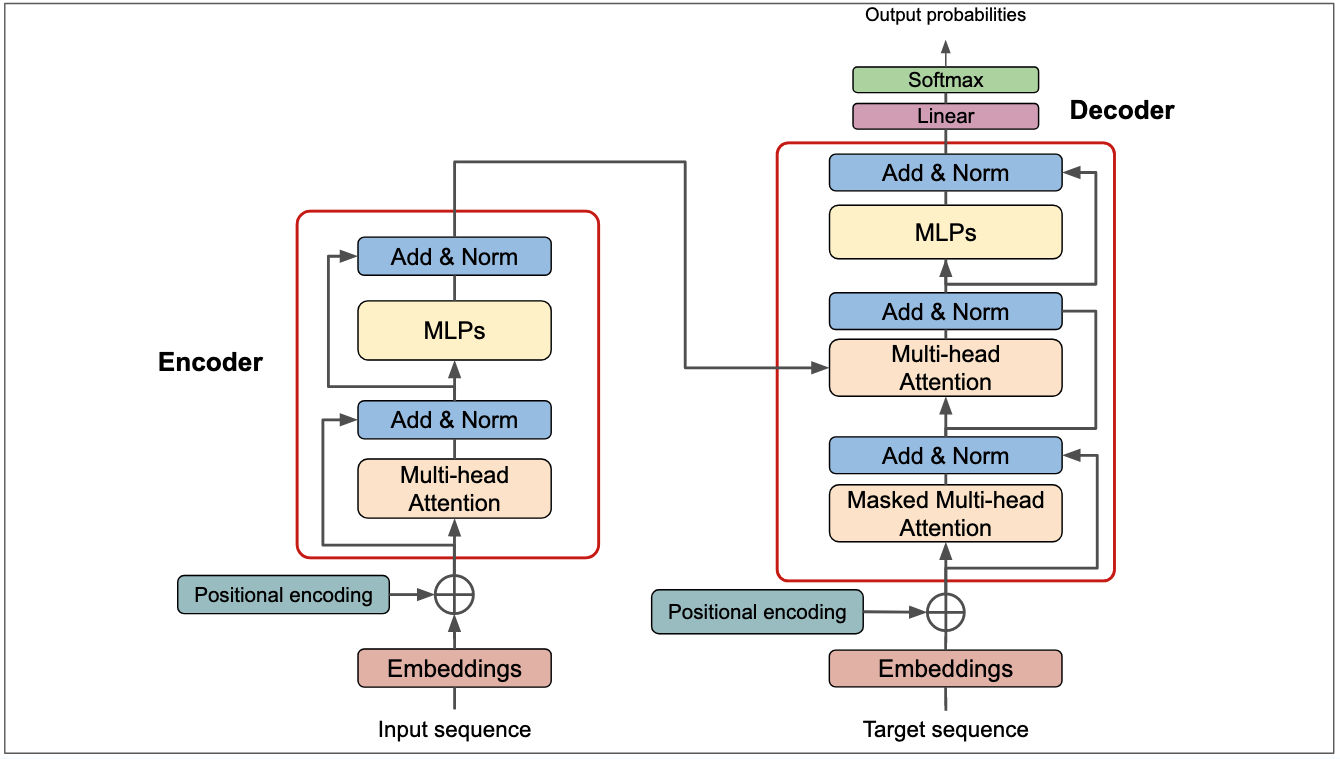
阿里巴巴开源国内最大参数规模大语言模型——高达720亿参数规模的Qwen-72B发布!还有一个可以在手机上运行的18亿参数的Qwen-1.8B
Qwen系列是阿里巴巴开源的一系列大语言模型。在此前的开源中,阿里巴巴共开源了3个系列的大模型,分别是70亿参数规模和140亿参数规模的Qwen-7B和Qwen-14B,还有一个是多模态大模型Qwen-VL。而此次阿里巴巴开源了720亿参数规模的Qwen-72b,是目前国内最大参数规模的开源大语言模型,应该也是全球范围内首次有和Llama2-70b同等规模的大语言模型开源。