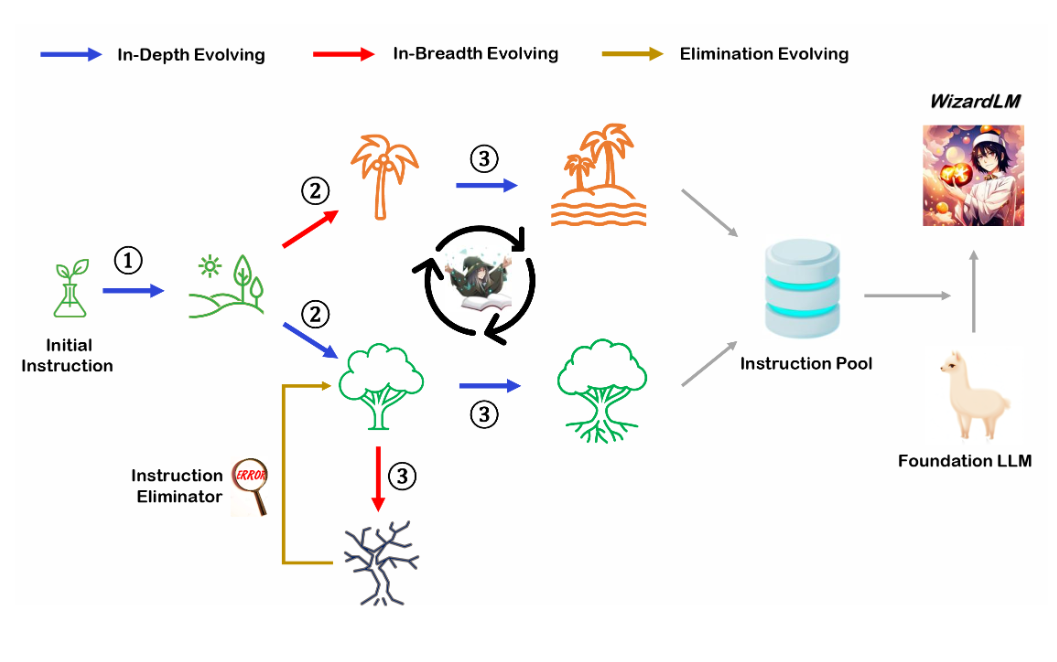
如何微调大语言模型?吴恩达联合LaminiAI最新一个小时短课教会大模型微调!这次是面向中级水平人员~
当谈及人工智能的巨大进步,大模型的崛起无疑是其中的一个重要里程碑。这些大模型,如GPT-3,已经展现出令人惊叹的语言生成和理解能力,但是为了让它们在特定任务上发挥最佳性能,大模型微调(Fine-tuning)是一种非常优秀的方法。微调是一种将预训练的大型模型进一步优化,以适应特定任务或领域的过程。但微调并不是很简单,今天吴恩达联合Lamini推出了全新的大模型微调短课《Finetuning Large Language Models》。