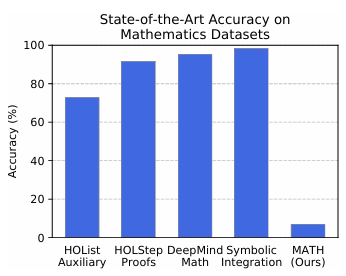
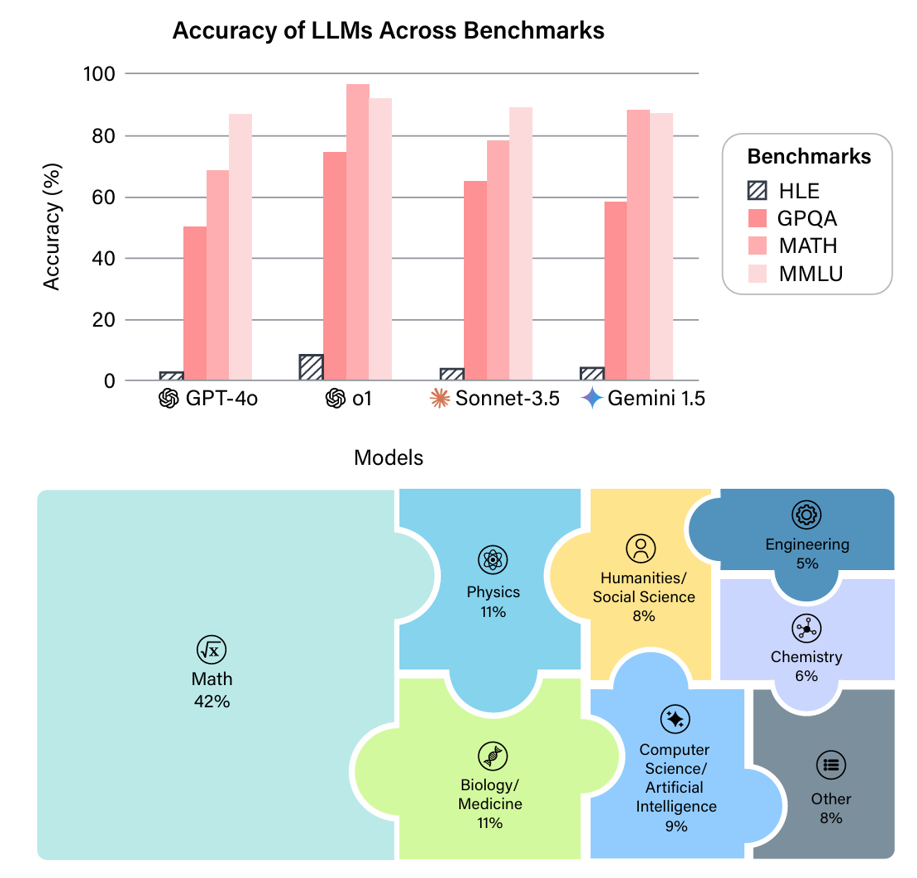
GPQA: 可以防止使用谷歌作弊的研究生级别难度的大模型专业能力评测基准(A Graduate-Level Google-Proof Q&A Benchmark)
研究生级别的 **Google 防查找问答基准测试**(即Graduate-Level Google-Proof Q&A Benchmark,简称 GPQA)是大型语言模型(LLM)面临的最具挑战性的评估之一。GPQA 旨在推动人工智能能力的极限,提供一个严格的测试平台,不仅评估模型的事实记忆能力,还考察其在专业科学领域的深度推理和理解能力。本篇博文将客观介绍 GPQA,涵盖它的起源、目的、组成部分,以及领先的大型语言模型在这个高要求基准测试中的表现。