
介绍 AIME 2025:评估大型语言模型高级数学推理能力的基准
随着大语言模型(LLM)的发展越来越快,我们需要更好的方法来评估它们到底有多“聪明”,特别是在处理复杂数学问题的时候。AIME 2025 就是这样一个工具,它专门用来测试当前 AI 在高等数学推理方面的真实水平。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
随着大语言模型(LLM)的发展越来越快,我们需要更好的方法来评估它们到底有多“聪明”,特别是在处理复杂数学问题的时候。AIME 2025 就是这样一个工具,它专门用来测试当前 AI 在高等数学推理方面的真实水平。
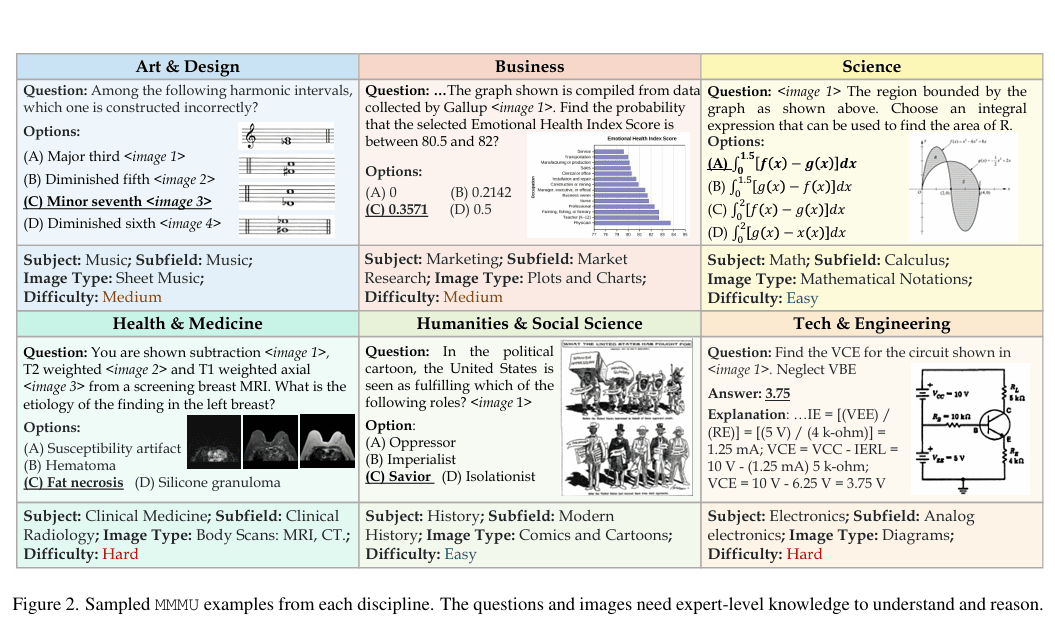
大规模多学科多模态理解与推理基准(MMMU)于2023年11月推出,是一种用于评估多模态模型的复杂工具。该基准测试人工智能系统在需要大学水平学科知识和深思熟虑推理的任务上的能力。与之前的基准不同,MMMU强调跨多个领域的先进感知和推理,旨在衡量朝专家级人工智能通用智能(AGI)的进展。
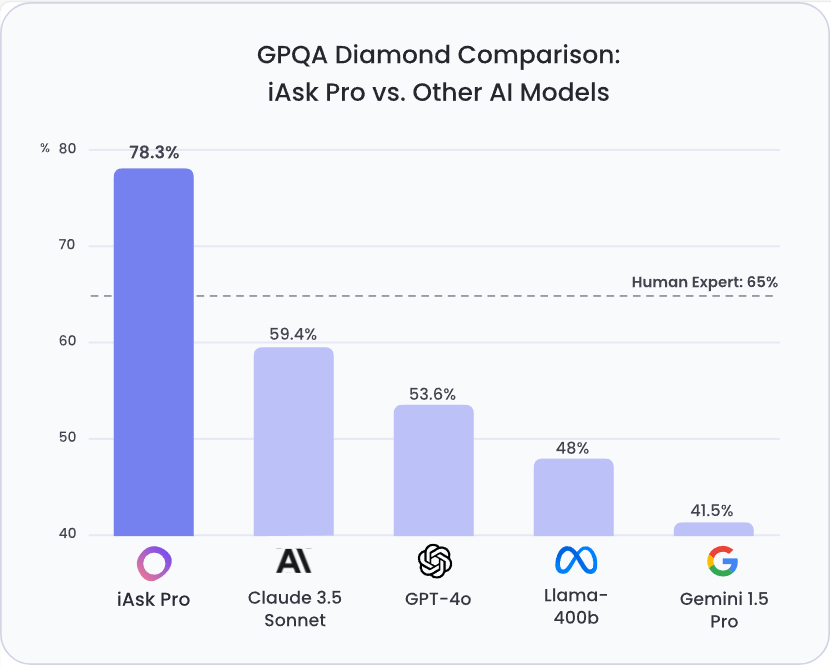
通用人工智能(AGI)的进步需要可靠的评估基准。GPQA (Grade-Level Problems in Question Answering) Diamond 基准旨在衡量模型在需要深度推理和领域专业知识问题上的能力。该基准由纽约大学、CohereAI 及 Anthropic 的研究人员联合发布,其相关论文可在 arXiv 上查阅 (https://arxiv.org/pdf/2311.12022 )。GPQA Diamond是GPQA系列中最高质量的评测数据,包含198条结果。

研究生级别的 **Google 防查找问答基准测试**(即Graduate-Level Google-Proof Q&A Benchmark,简称 GPQA)是大型语言模型(LLM)面临的最具挑战性的评估之一。GPQA 旨在推动人工智能能力的极限,提供一个严格的测试平台,不仅评估模型的事实记忆能力,还考察其在专业科学领域的深度推理和理解能力。本篇博文将客观介绍 GPQA,涵盖它的起源、目的、组成部分,以及领先的大型语言模型在这个高要求基准测试中的表现。

LiveCodeBench 由加州大学伯克利分校、麻省理工学院和康奈尔大学的研究人员开发,是一个先进的评测基准套件,专门用于严格评估大语言模型 (LLMs) 在代码处理方面的能力,并解决现有基准测试的局限性。通过引入实时更新的问题集和多维度评估方法,LiveCodeBench 确保对 LLM 进行公平、全面和稳健的评估。

短短两年间,AI技术的进步为软件工程带来了新的可能性。然而,这些模型在真实世界的软件工程任务中究竟能发挥多大的作用?它们能否通过完成实际的软件工程任务来赚取可观的收入?为了验证大模型解决真实任务的能力和水平,OpenAI发布了一个全新的大模型评测基准SWE-Lancer来评测大模型这方面的能力。
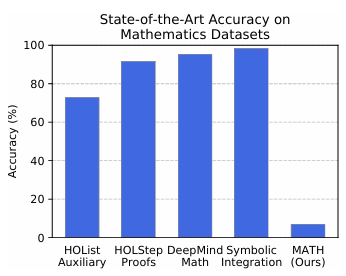
在评估大型语言模型(LLM)的数学推理能力时,MATH和MATH-500是两个备受关注的基准测试。尽管它们都旨在衡量模型的数学解题能力,但在发布者、发布目的、评测目标和对比结果等方面存在显著差异。
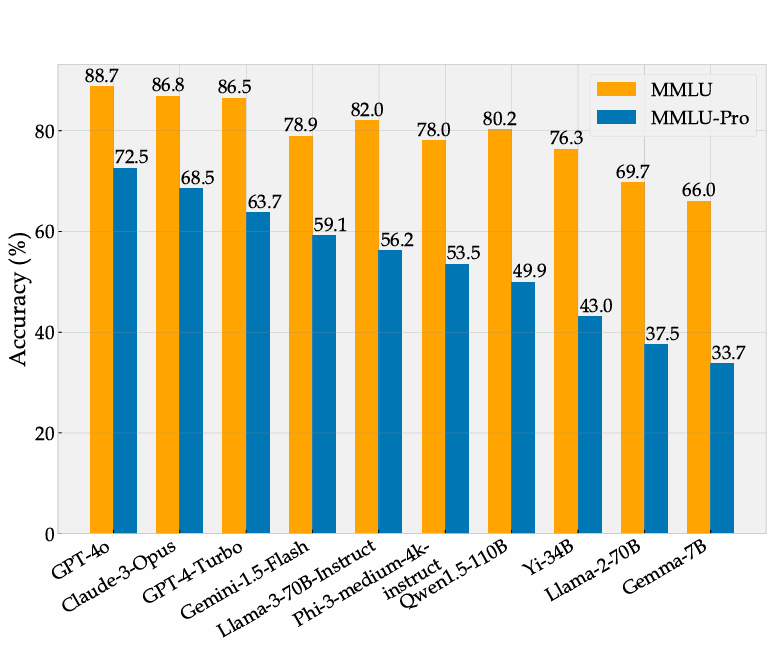
大模型已经对很多行业产生了巨大的影响,如何准确评测大模型的能力和效果,已经成为业界亟待解决的关键问题。生成式AI模型,如大型语言模型(LLMs),能够生成高质量的文本、代码、图像等内容,但其评测却相对很困难。而此前很多较早的评测也很难区分当前最优模型的能力。 以MMLU评测为例,2023年3月份,GPT-4在MMLU获得了86.4分之后,将近2年后的2024年年底,业界最好的大模型在MMLU上得分也就90.5,提升十分有限。 为此,滑铁卢大学、多伦多大学和卡耐基梅隆大学的研究人员一起提出了MMLU P
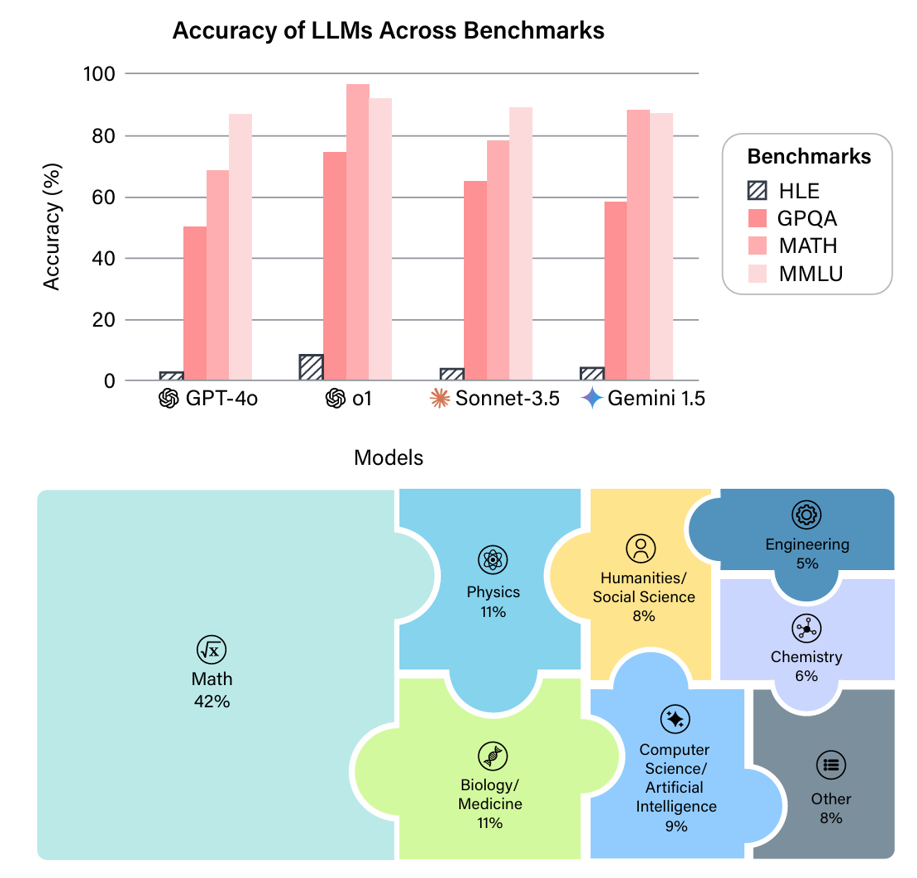
近年来,大语言模型(LLM)的能力飞速提升,但评测基准的发展却显得滞后。以广泛使用的MMLU(大规模多任务语言理解)为例,GPT-4、Claude等前沿模型已能在其90%以上的问题上取得高分。这种“评测饱和”现象导致研究者难以精准衡量模型在尖端知识领域的真实能力。为此,Safety for AI和Scale AI的研究人员推出了Humanity’s Last Exam大模型评测基准。这是一个全新的评测基准,旨在成为大模型“闭卷学术评测的终极考验”。
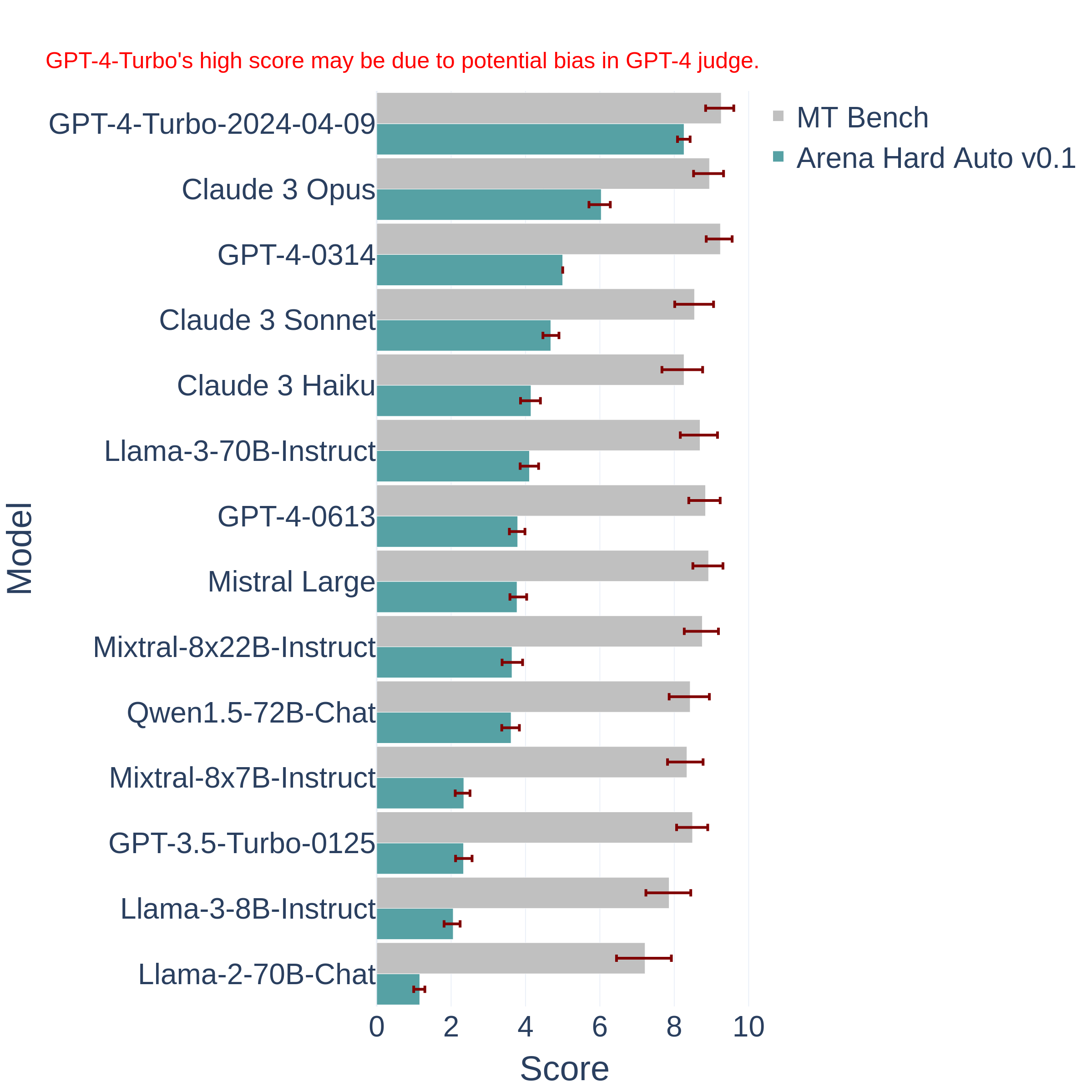
评估日益发展的大型语言模型(LLM)是一个复杂的任务。传统的基准测试往往难以跟上技术的快速进步,容易过时且无法捕捉到现实应用中的细微差异。为此,LM-SYS研究人员提出了一个全新的大模型评测基准——Arena Hard。这个平常基准是基于Chatbot Arena发展而来,相比较常规的评测基准,它更难也更全面。