
阿里发布第二代图像大模型:Qwen-Image-2.0,融合文本生成图片、图片编辑为一体全球目前排名第三!中文渲染很棒!但不开源~
就在刚刚,阿里宣布发布Qwen-Image-2.O模型,该模型是Qwen Image系列的最新版本,这个模型综合了此前的文本生成图片和图片编辑的能力,在文本渲染、生成PPT图片方面大幅提升。不过相比较之前的Qwen Image系列,该版本的模型并没有开源,目前在官网可以免费使用。
聚焦人工智能、大模型与深度学习的精选内容,涵盖技术解析、行业洞察和实践经验,帮助你快速掌握值得关注的AI资讯。
就在刚刚,阿里宣布发布Qwen-Image-2.O模型,该模型是Qwen Image系列的最新版本,这个模型综合了此前的文本生成图片和图片编辑的能力,在文本渲染、生成PPT图片方面大幅提升。不过相比较之前的Qwen Image系列,该版本的模型并没有开源,目前在官网可以免费使用。
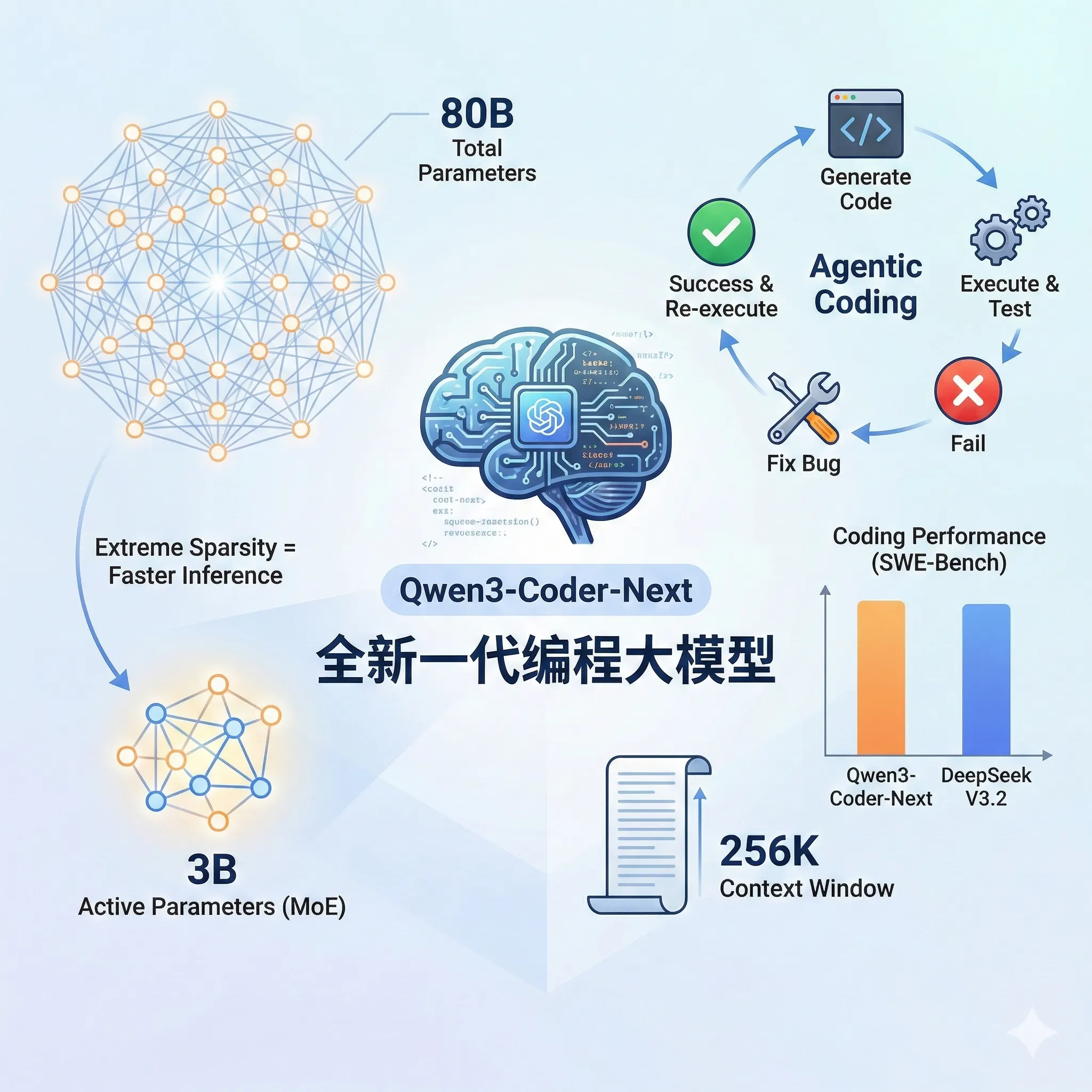
阿里开源了全新一代编程大模型Qwen3-Coder-Next,该模型是基于Qwen3-Next-80B-A3B-Base模型后训练得到,总参数规模800亿,激活参数仅30亿。也就是说,这个模型的推理速度基本和3B这种小规模参数差不多,但是它的评测结果,特别是在编程方面的评测与DeepSeek V3.2的水平差不多。

就在刚刚,阿里开源了全新的语音合成大模型Qwen3-TTS系列!本次开源的语音合成模型共5个版本,最小的仅0.6B参数规模,最大的模型参数也就1.7B,基本上手机端都可以运行。此次发布不仅在性能上宣称超越了许多商业级闭源模型(如 OpenAI 的 GPT-4o-Audio 和 ElevenLabs),更重要的这应该是阿里通义千问团队首次开源语音合成系列大模型。

就在刚刚,阿里巴巴正式免费开源了两款全新的多模态模型——Qwen3-VL-Embedding(多模态向量模型)和 Qwen3-VL-Reranker(多模态重排序模型),首次在开源体系中系统性补齐了多模态 RAG 在“向量化检索 + 精排重排”两个关键环节上的能力空白。这两个模型是基于强大的Qwen3-VL基础模型构建的专用多模态向量与重排(Reranking)模型。

就在今日,阿里巴巴Qwen团队重磅推出Qwen3-VL-2B和Qwen3-VL-32B两款视觉语言模型,这些dense架构的创新之作,将多模态AI的强大能力压缩进更紧凑的框架中,显著降低了部署门槛。 作为Qwen3系列的最新扩展,它们在保持顶级性能的同时,支持从边缘设备到云端的无缝应用——想象一下,一款手机App就能实时分析2小时视频,或从模糊手写笔记中提取精确信息。这不仅仅是参数缩减,更是AI普惠化的关键一步,帮助开发者以更低的成本实现视觉智能的突破。

就在刚才,阿里云Qwen团队推出了两个多模态理解大模型Qwen3-VL-4B和Qwen3-VL-8B,本次发布的模型是较小参数规模的模型,可以用于消费级硬件(手机/PC)等,且都是稠密架构。

今日,QwenTeam 正式发布了全新一代多模态视觉语言模型 —— Qwen3-VL 系列。这是 Qwen 家族迄今为止最强大的视觉语言模型,在视觉感知、跨模态推理、长上下文理解、空间推理和智能代理交互等多个维度全面提升。旗舰开源模型 Qwen3-VL-235B-A22B 已经上线,并提供 Instruct 和 Thinking 两个版本,前者在视觉感知上全面对标并超过 Gemini 2.5 Pro,后者则在多模态推理基准上创下新纪录,成为开源阵营的最强视觉理解大模型。

几个小时前,阿里一次更新了3个大模型,分别是开源的全模态大模型Qwen3-Omni、开源的图像编辑大模型Qwen3-Image-Edit和不开源的语音识别大模型Qwen3-TTS。本次发布的3个模型均为多模态大模型,可以说阿里的大模型真的是全面开花,节奏很快!

继阿里刚发布Qwen3-ASR模型之后,Qwen团队又在社区提交了全新的Qwen3-Next代码。这意味着阿里即将开源Qwen3家族的新成员。这个模型最大的特点是架构变化很大,与此前Qwen系列很不一样。

阿里发布了全新的语音识别大模型Qwen3-ASR-Flash,该模型是Qwen3系列模型中首个语音识别大模型,中英文语音识别错误率低于GPT-4o-transcribe和Gemini 2.5 Pro。不过,该模型目前仅通过API提供,不开源!

阿里巴巴的 Qwen Code 是一款开源的命令行 AI 工具,旨在提升开发者的编程效率,特别适用于处理大型代码库和复杂的开发任务。 2025年8月9日,阿里宣布提供每天2000次的免费Qwen Code服务,应该是满足大多数开发者的日常需求了。

就在刚才,阿里开源了Qwen Image大模型,这是阿里千问团队开源的高质量图片生成和编辑的大模型。这份发布迅速在AI社区引起了广泛关注,其核心并非又一个单纯追求图像美学或真实感的模型,而是直指一个长期存在的行业痛点:在图像中进行复杂、精准、尤其是高保真的多语言文本渲染。

阿里今天开源了一个Qwen3-235B-A22B模型的小幅更新版本,命名为Qwen3-235B-A22B-Thinking-2507,这是一个只支持带推理过程的模型,而四天前,阿里还开源了Qwen3-235B-A22B-Instruct-2507,一个不支持推理过程的模型。这2个版本模型去除了Qwen3此前的一个模型的混合架构模式(即一个模型同时支持thinking和non-thinking),而是拆分成2个不同的版本。阿里官方说这是从社区获得了反馈之后决策的。

阿里宣布开源第三代编程大模型Qwen3-Coder-480B-A35B,该模型是Qwen3编程大模型中第一个开源的版本,同时官方还基于Google的Gemini CLI改造并开源了阿里自己的命令行编程工具Qwen Code,完全免费使用。

2025年6月26日,阿里达摩院正式发布了全新的Qwen VLo大模型。这是继QwenVL和Qwen2.5 VL后,阿里在多模态大模型领域又一具有里程碑意义的创新。Qwen VLo是一款统一的多模态理解与生成模型,不仅具备深度理解图片与文本内容的能力,更能基于这种理解实现高质量和高度一致的图像生成与编辑,真正跨越了“感知”与“创造”的界限。

Qwen3 是阿里于 2025 年 6 月开源的新一代大模型系列,共发布了 8 个不同参数规模的模型,覆盖从 6 亿到 2350 亿参数的范围,融合了稠密模型和 MoE 架构。值得注意的是,此次未包含此前广受关注的 Qwen-72B 稠密模型版本,阿里表示从 Qwen3 起,超过 30B 参数的模型将统一采用 MoE 架构以优化性能和效率。

阿里巴巴Qwen团队发布了全新的Qwen3 Embedding系列模型,这是一套基于Qwen3基础模型构建的专用文本向量与重排(Reranking)模型。该系列模型凭借Qwen3强大的多语言理解能力,在多项文本向量与重排任务的Benchmark上达到了SOTA水平,其中8B尺寸的向量模型在MTEB多语言排行榜上排名第一。Qwen3 Reranker模型在多个评测基准上同样大幅超越了现有的主流开源竞品。
阿里巴巴刚刚开源了第三代千问大模型,Qwen3系列包含了8个不同参数规模的大模型,最大达到2350亿参数规模,最小仅6亿参数规模。本次发布的Qwen3系列是推理大模型和常规的大模型混合版本,即Qwen3可以根据输入问题的情况自动选择是否进行推理。
Qwen2.5-Omni-7B是阿里巴巴发布的一款端到端全模态大模型,支持文本、图像、音频、视频(无音频轨)的多模态输入与实时生成能力,可同步输出文本与自然语音的流式响应。目前,该模型在HuggingFace以Apache2.0协议开源,可以免费商用授权。
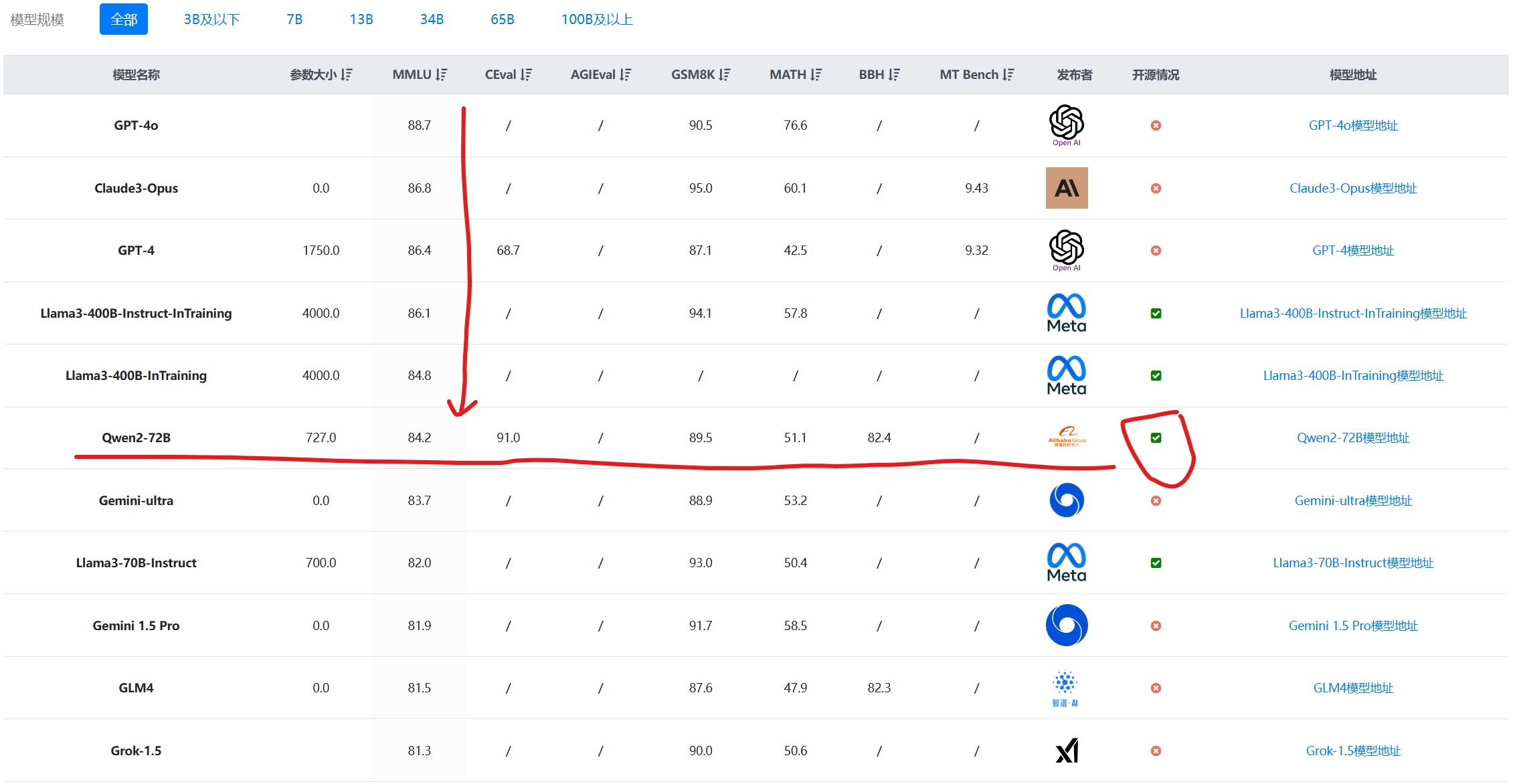
Qwen系列大语言模型是阿里巴巴开源的大语言模型。最早的Qwen模型在2023年8月份开源,当时只有70亿参数规模模型,随后阿里巴巴不断开源新的模型,最高参数规模达到了700亿,版本也从1.0升级到2024年3月份的1.5,再到今天发布的Qwen2系列。Qwen已经开源了几十个不同参数规模的大模型。此次发布的Qwen2.0系列不仅在评测任务上超过了现有的开源模型,也在实际应用中有非常好的表现。
Qwen1.5系列是阿里开源的一系列大语言模型,也是目前为止最强开源模型之一。Qwen1.5是Qwen2的beta版本,此前开源的模型最大参数规模都是720亿,和第一代模型一样。就在刚刚,阿里开源了1100亿参数规模的Qwen1.5-110B模型。评测结果显示MMLU略超Llama3-70B和Mixtral-8×22B。我们实测结果,相比Qwen1.5-72B模型来说,复杂任务的逻辑提升比较明显!
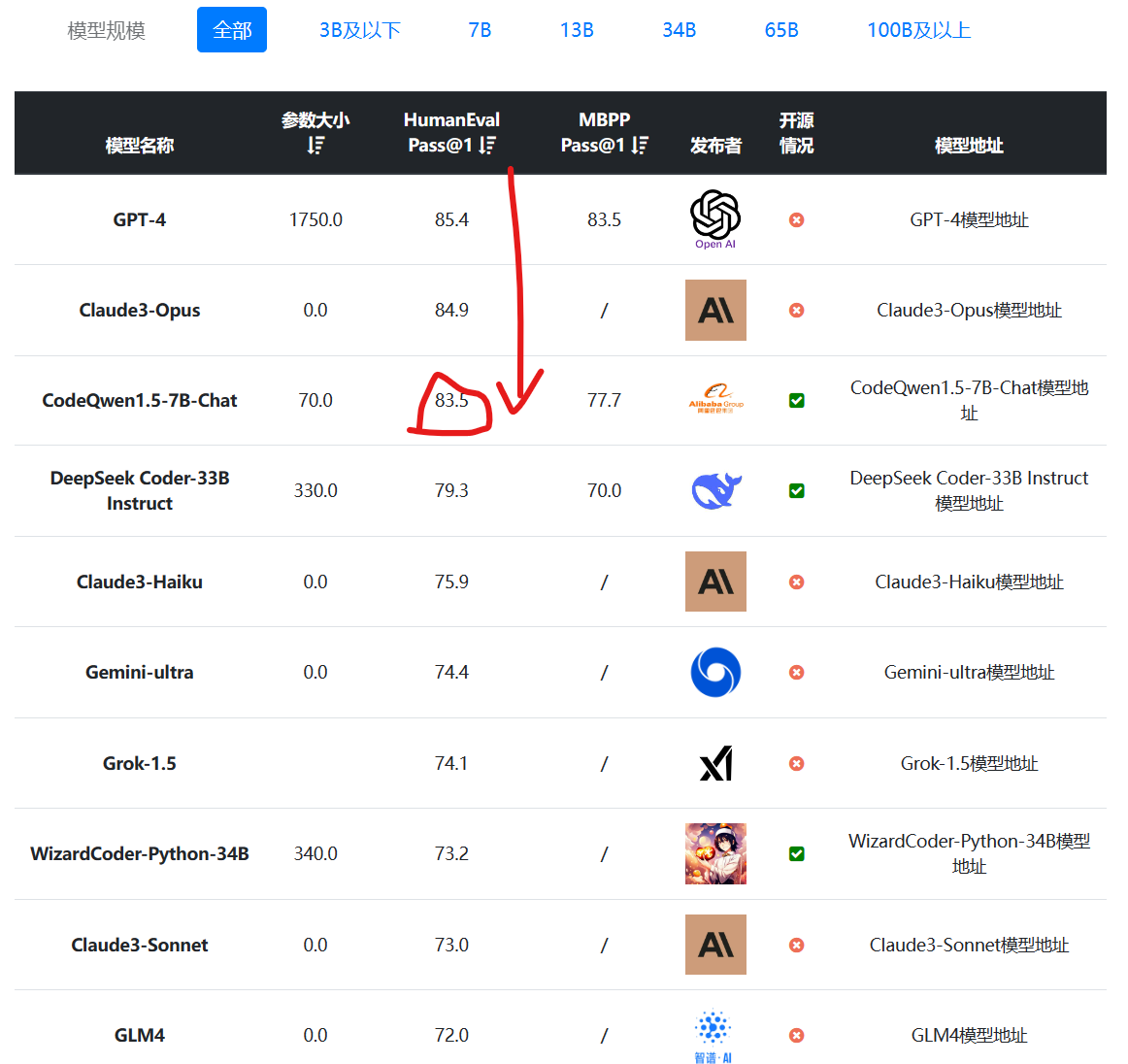
编程大模型是当前大语言模型里面最重要的一类。一般是基础大模型在预训练之后,加入代码数据集继续训练得到。在代码补全、代码生成方面一般强于常规的大语言模型。阿里最新开源的70亿参数大模型CodeQwen1.5-7B在HumanEval评测结果上超过了GPT-4早期版本,表现异常地好!
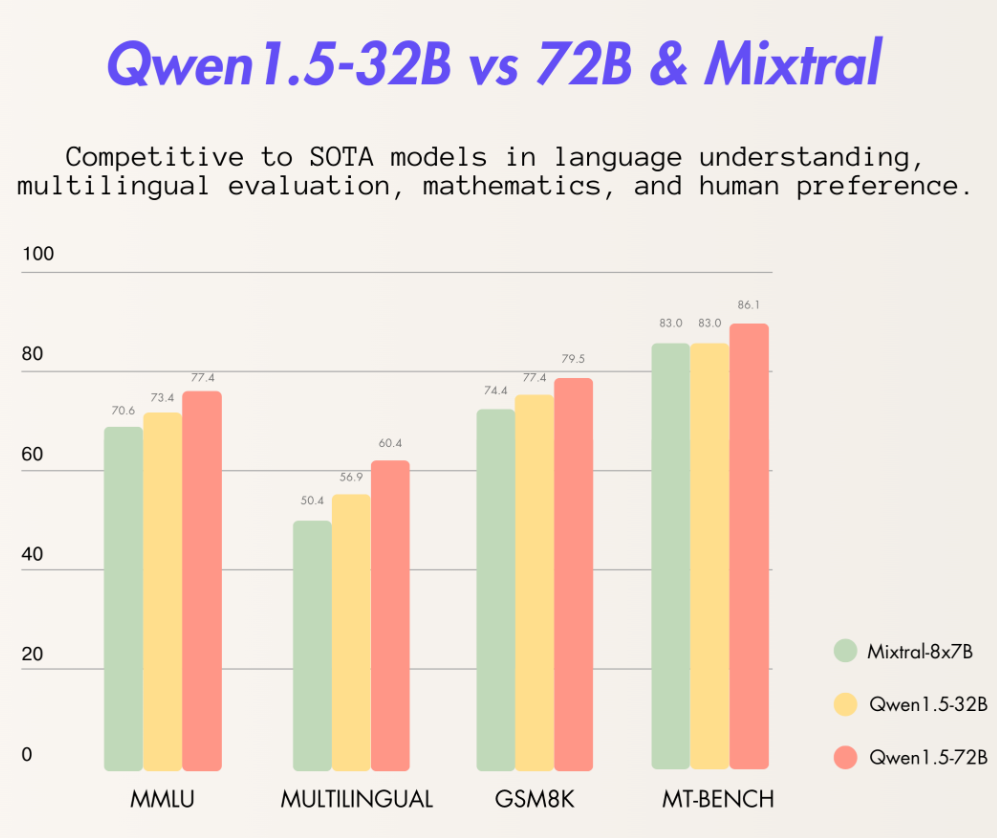
阿里巴巴最新开源了320亿参数的大语言模型Qwen1.5-32B,这个模型在各项评测结果中都略超此前最强开源大模型Mixtral 8×7B MoE,比720亿参数的Qwen-1.5-72B模型略差。但是一半的参数意味着只有一半的显存,这样的性价比极高。
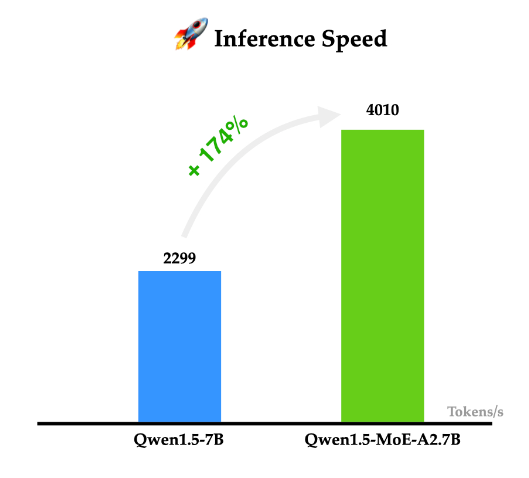
阿里巴巴的通义千问一直是开源领域最强大的大模型之一。就在今天,阿里巴巴首次开源了他们家的MoE技术大模型Qwen1.5-MoE-A2.7B,这个模型是使用现有的Qwen-1.8B模型作为起点,通过类似merge技术进行合并得到的。